The \(\chi^2\) Distribution¶
\(\chi^2\) Test Statistic¶
If we make \(n\) ranom samples (observations) from Gaussian (Normal) distributions with known means, \(\mu_i\), and known variances, \(\sigma_i^2\), it is seen that the total squared deviation,
follows a \(\chi^2\) distribution with \(n\) degrees of freedom.
Probability Distribution Function¶
The \(\chi^2\) probability distribution function for \(k\) degrees of freedom (the number of parameters that are allowed to vary) is given by
where if there are no constrained variables the number of degrees of freedom, \(k\), is equal to the number of observations, \(k=n\). The p.d.f. is often abbreviated in notation from \(f\left(\chi^2\,;k\right)\) to \(\chi^2_k\).
A reminder that for integer values of \(k\), the Gamma function is \(\Gamma\left(k\right) = \left(k-1\right)!\), and that \(\Gamma\left(x+1\right) = x\Gamma\left(x\right)\), and \(\Gamma\left(1/2\right) = \sqrt{\pi}\).
Mean¶
Letting \(\chi^2=z\), and noting that the form of the Gamma function is
it is seen that the mean of the \(\chi^2\) distribution \(f\left(\chi^2 ; k\right)\) is
Variance¶
Likewise, the variance is
such that the standard deviation is
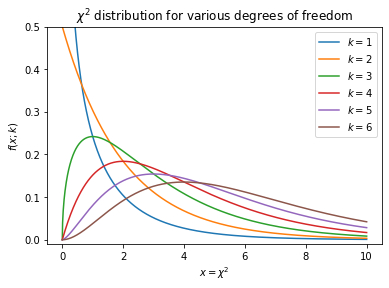
Given this information we now plot the \(\chi^2\) p.d.f. with various numbers of degrees of freedom to visualize how the distribution’s behaviour
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
# Plot the chi^2 distribution
x = np.linspace(0.0, 10.0, num=1000)
[plt.plot(x, stats.chi2.pdf(x, df=ndf), label=fr"$k = ${ndf}") for ndf in range(1, 7)]
plt.ylim(-0.01, 0.5)
plt.xlabel(r"$x=\chi^2$")
plt.ylabel(r"$f\left(x;k\right)$")
plt.title(r"$\chi^2$ distribution for various degrees of freedom")
plt.legend(loc="best")
plt.show();
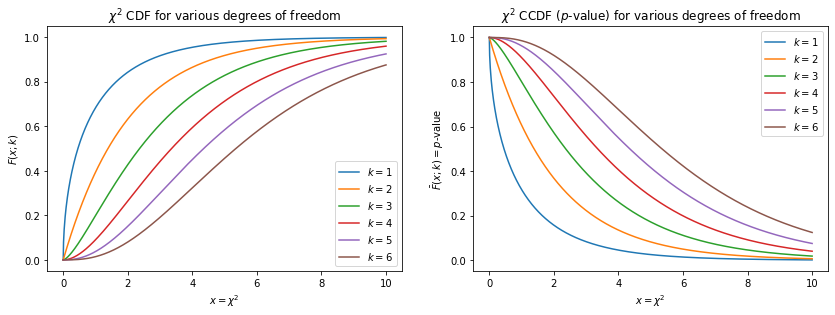
Cumulative Distribution Function¶
The cumulative distribution function (CDF) for the \(\chi^2\) distribution is (letting \(z=\chi^2\))
Noting the form of the lower incomplete gamma function is
and the form of the regularized Gamma function is
it is seen that
Thus, it is seen that the compliment to the CDF (the complementary cumulative distribution function (CCDF)),
represents a one-sided (one-tailed) \(p\)-value for observing a \(\chi^2\) given a model — that is, the probability to observe a \(\chi^2\) value greater than or equal to that which was observed.
def chi2_ccdf(x, df):
"""The complementary cumulative distribution function
Args:
x: the value of chi^2
df: the number of degrees of freedom
Returns:
1 - the cumulative distribution function
"""
return 1.0 - stats.chi2.cdf(x=x, df=df)
x = np.linspace(0.0, 10.0, num=1000)
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(14, 4.5))
for ndf in range(1, 7):
axes[0].plot(x, stats.chi2.cdf(x, df=ndf), label=fr"$k = ${ndf}")
axes[1].plot(x, chi2_ccdf(x, df=ndf), label=fr"$k = ${ndf}")
axes[0].set_xlabel(r"$x=\chi^2$")
axes[0].set_ylabel(r"$F\left(x;k\right)$")
axes[0].set_title(r"$\chi^2$ CDF for various degrees of freedom")
axes[0].legend(loc="best")
axes[1].set_xlabel(r"$x=\chi^2$")
axes[1].set_ylabel(r"$\bar{F}\left(x;k\right) = p$-value")
axes[1].set_title(r"$\chi^2$ CCDF ($p$-value) for various degrees of freedom")
axes[1].legend(loc="best")
plt.show();
Binned \(\chi^2\) per Degree of Freedom¶
TODO
References¶
[1] G. Cowan, Statistical Data Analysis, Oxford University Press, 1998
[2] G. Cowan, “Goodness of fit and Wilk’s theorem”, Notes, 2013