Unweighted and Weighted Means¶
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
import matplotlib.patches as mpathces
Maximum Likelihood Estimator motivated “derivations”¶
Unweighted Means¶
If we make \(n\) identical statistically independent (isi) measurements of a random variable \(x\), such that the measurements collected form data \(\vec{x} = \left\{x_i, \cdots, x_n\right\}\), from a Gaussian (Normal) distribution,
then
and so \(L\) is maximized with respect to a variable \(\alpha\) when \(-\ln L\) is minimized,
Thus, \(L\) is maximized when
which occurs for
such that the best estimate for true parameter \(\mu\) is
and \(L\) is maximized when
which occurs for
which is
However, \(\mu\) is an unknown true parameter, and the best estimate of it is \(\hat{\mu}\), which is in no manner required to be equal to \(\mu\). Thus, the best estimate of \(\sigma\) is
If the separation from the mean of each observation, \(\left(x_i - \bar{x}\right) = \delta x = \text{constant}\), are the same then the uncertainty on the mean is found to be
which is often referred to as the “standard error”.
So, for a population of measurements sampled from a distribution, it can be said that the sample mean is
and the standard deviation of the sample is
Weighted Means¶
Assume that \(n\) individual measurements \(x_i\) are spread around (unknown) true value \(\theta\) according to a Gaussian distribution, each with known width \(\sigma_i\).
This then leads to the likelihood function
and so negative log-likelihood
As before, \(L\) is maximized with respect to a variable \(\alpha\) when \(-\ln L\) is minimized,
and so \(L\) is maximized with respect to \(\theta\) when
which occurs for
which is
Note that by defining “weights” to be
this can be expressed as
making the term “weighted mean” very transparent.
To find the standard deviation on the weighted mean, we first look to the variance, \(\sigma^2\). [4]
Thus, it is seen that the standard deviation on the weighted mean is
Notice that in the event that the uncertainties are uniform for each observation, \(\sigma_i = \delta x\), the above yields the same result as the unweighted mean. \(\checkmark\)
After this aside it is worth pointing out that [1] have a very elegant demonstration that
So, the average of \(n\) measurements of quantity \(\theta\), with individual measurements, \(x_i\), Gaussianly distributed about (unknown) true value \(\theta\) with known width \(\sigma_i\), is the weighted mean
with weights \(w_i = \sigma_i^{-2}\), with standard deviation on the weighted mean
Specific Examples¶
Given the measurements
with uncertanties
x_data = [10, 9, 11]
x_uncertainty = [1, 2, 3]
numerator = sum(x / (sigma_x ** 2) for x, sigma_x in zip(x_data, x_uncertainty))
denominator = sum(1 / (sigma_x ** 2) for sigma_x in x_uncertainty)
print(f"hand calculated weighted mean: {numerator / denominator}")
hand calculated weighted mean: 9.897959183673468
Using NumPy’s average method
# unweighted mean
np.average(x_data)
10.0
x_weights = [1 / (uncert ** 2) for uncert in x_uncertainty]
# weighted mean
weighted_mean = np.average(x_data, weights=x_weights)
print(weighted_mean)
9.897959183673468
# no method to do this in NumPy!?
sigma = np.sqrt(1 / np.sum(x_weights))
print(f"hand calculated uncertaintiy on weighted mean: {sigma}")
hand calculated uncertaintiy on weighted mean: 0.8571428571428571
# A second way to find the uncertainty on the weighted mean
summand = sum((x * w) for x, w in zip(x_data, x_weights))
np.sqrt(np.average(x_data, weights=x_weights) / summand)
0.8571428571428571
Let’s plot the data now and take a look at the results
def draw_weighted_mean(data, errors, w_mean, w_uncert):
plt.figure(1)
# the data to be plotted
x = [i + 1 for i in range(len(data))]
x_min = x[x.index(min(x))]
x_max = x[x.index(max(x))]
y = data
y_min = y[y.index(min(y))]
y_max = y[y.index(max(y))]
err_max = errors[errors.index(max(errors))]
# plot data
plt.errorbar(x, y, xerr=0, yerr=errors, fmt="o", color="black")
# plot weighted mean
plt.plot((x_min, x_max), (w_mean, w_mean), color="blue")
# plot uncertainty on weighted mean
plt.plot(
(x_min, x_max),
(w_mean - w_uncert, w_mean - w_uncert),
color="gray",
linestyle="--",
)
plt.plot(
(x_min, x_max),
(w_mean + w_uncert, w_mean + w_uncert),
color="gray",
linestyle="--",
)
# Axes
plt.xlabel("Individual measurements")
plt.ylabel("Value of measruement")
# view range
epsilon = 0.1
plt.xlim(x_min - epsilon, x_max + epsilon)
plt.ylim([y_min - err_max, 1.5 * y_max + err_max])
# ax = figure().gca()
# ax.xaxis.set_major_locator(MaxNLocator(integer=True))
# Legends
wmean_patch = mpathces.Patch(
color="blue", label=fr"Weighted mean: $\mu={w_mean:0.3f}$"
)
uncert_patch = mpathces.Patch(
color="gray",
label=fr"Uncertainty on the weighted mean: $\pm{w_uncert:0.3f}$",
)
plt.legend(handles=[wmean_patch, uncert_patch])
plt.show()
draw_weighted_mean(x_data, x_uncertainty, weighted_mean, sigma)
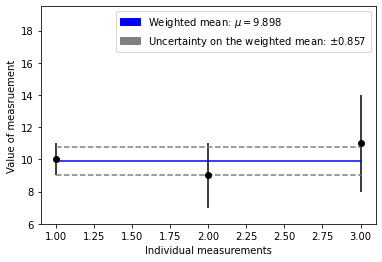
Now let’s do this again but with data that are Normally distributed about a mean value
true_mu = np.random.uniform(3, 9)
true_sigma = np.random.uniform(0.1, 2.0)
n_samples = 20
samples = np.random.normal(true_mu, true_sigma, n_samples).tolist()
gauss_errs = np.random.normal(2, 0.4, n_samples).tolist()
weights = [1 / (uncert ** 2) for uncert in gauss_errs]
draw_weighted_mean(
samples,
gauss_errs,
np.average(samples, weights=weights),
np.sqrt(1 / np.sum(weights)),
)
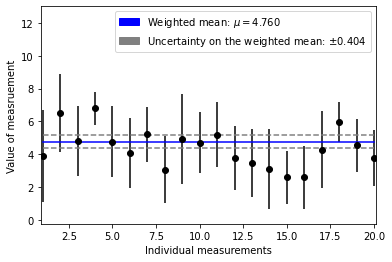
References¶
Data Analysis in High Energy Physics, Behnke et al., 2013, \(\S\) 2.3.3.1
Statistical Data Analysis, Glen Cowan, 1998
University of Marlyand, Physics 261, Notes on Error Propagation
Physics Stack Exchange, How do you find the uncertainty of a weighted average?